Компания VMware очень много внимания уделяет концепции обеспечения непрерывности бизнеса (Business Continuity), одной из составляющих которой, безусловно, является непрерывная работа ИТ-служб. Простои оборудования и сервисов обходятся компаниям в ощутимые убытки или недополучение прибыли. Поэтому очень важно поддерживать непрерывно работающую и эффективную инфраструктуру, оперативно реагирующую на изменения. В этих условиях концепция виртуализации и консолидации серверов (Server Virtualization and Consolidation), а также десктопов (Virtual Desktop Infrastructure) – одни из важнейших и, на сегодняшний день, необходимых факторов построения современного датацентра.
Первую часть статьи «Размышления о запланированных и незапланированных простоях в рамках VMware Virtual Infrastructure и ESX Server» можно прочитать здесь:
Как видно из рисунка 10-20% всех простоев приходятся на внеплановые простои, возникающие вследствие выхода из строя оборудования или ПО, неполадок в сети, авариях, катастрофах и т.п. Это простои, приводящие к самым большим убыткам вследствие их неожиданности и непредсказуемости (все ломается в самый неподходящий момент).
Компания VMware предлагает нам в рамках виртуальной инфраструктуры VMware Virtual Infrastructure сократить потери от внеплановых простоев для подавляющего большинства приложений, а для некоторых – вовсе свести их к 0. Как ей это удается? Давайте посмотрим:
VMware High Availability – механизм обеспечения высокой доступности виртуальных машин, позволяющий в случае отказа физического сервера ESX перезапустить виртуальную машину с общей системы хранения.
Очевидно, что VMware HA не устраняет внеплановые простои, а «лишь» в разы сокращает время возобновления работоспособности сервиса в виртуальной машине. Кроме того, HA не защищает от сбоя на уровне приложения или операционной системы. Также, в случае выхода из строя общей системы хранения – VMware HA нам не поможет. Поэтому компания VMware приготовила нам еще несколько полезных продуктов.
VMware Virtual Machine Failure Monitoring (VMFT) – механизм обеспечения высокой доступности сервиса на уровне одной виртуальной машины.
Как это работает: специальное ПО VMware Tools, устанавливаемое в гостевой ОС виртуальной машины, посылает сигналы доступности (heartbeats) серверу ESX. В случае отказа операционной системы (например, зависание вследствие сбоя драйвера), сигналы перестают поступать, и механизм VMFT перезапускает виртуальную машину. Таким образом, сокращается время простоя при отказе программного обеспечения (в данном случае ОС).
VMware Fault Tolerance (VMFT) - механизм, обеспечивающий доступность виртуальной машины, даже в случае выхода из строя физического хост-сервера ESX, на котором она запущена. Звучит как магия, не правда ли? Однако никакой магии нет. Достигается это средством того, что на другом сервере запущена «теневая» копия виртуальной машины, синхронизированная с первой. В случае отказа первого физического сервера ESX, на втором сервере копия виртуальной машины выходит из «тени».
Становится понятно, что VMFT требует выделения двойной мощности на серверах ESX для виртуальной машины, а отсюда следует, что таким образом нужно обеспечивать доступность только самых критичных сервисов. По сути VMFM+VMFT являются хорошей альтернативой кластеру Microsoft или Veritas (не перехватывается только отказ приложения).
NIC Teaming/ HBA Multipathing - по сути введение избыточности сетевых интерфейсов на случай отказа сетевых устройств или соединений. Что умеет делать NIC Teaming:
Балансирует нагрузку между несколькими сетевыми интерфейсами. При отказе одного из интерфейсов остальные интерфейсы продолжают обеспечивать сетевое взаимодействие.
Адаптеры работают в режиме отказоустойчивости. Один адаптер активен, второй не работает. В случае отказа первого адаптера, второй берет на себя функции по сетевому взаимодействию.
Оба этих режима обеспечивают нулевое время простоя в случае отказа адаптера. В первом случае уменьшается срок службы адаптера, но используется больше интерфейсов, в другом случае – срок службы пассивного адаптера увеличивается, но уменьшается общая пропускная способность.
В случае HBA Multipathing пока допускается использовать только один HBA-адаптер для доступа к SAN, второй же адаптер работает в режиме обеспечения отказоустойчивости. Алгоритм балансировки нагрузки Round Robin пока находится в статусе «experimental» и не рекомендуется к использованию в производственной среде.
И для SAN, и для LAN необходимо обеспечить резервирование на уровне коммутаторов, так чтобы при выходе из строя одного из коммутаторов фабрики – сетевое взаимодействие виртуальных машин не прерывалось.
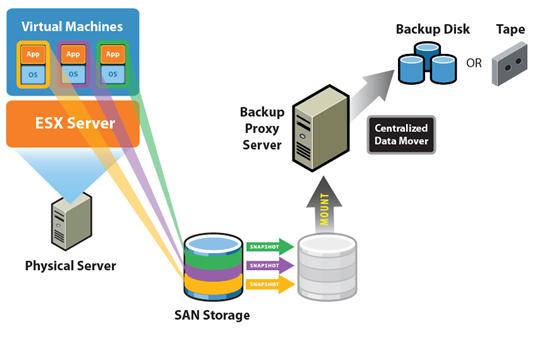
VMware Consolidated Backup – средство резервного копирования виртуальных машин без загрузки сети производственной среды Ethernet и без необходимости их остановки. VMware VCB – всего лишь фреймворк для резервного копирования, предполагающий, что его будут использовать сторонние продукты для резервного копирования, например, Veritas BackupExec. Тем не менее, VCB можно использовать и отдельно, разрабатывая сценарии для резервного копирования.
Основное отличие VCB от традиционных средств резервного копирования – возможность целиком сохранить образ работающей (!) виртуальной машины. Поскольку виртуальная машина это набор файлов, ее просто скопировать и просто восстановить. При этом не требуется установка агентов в гостевые ОС виртуальных машин. С помощью VCB существенно сокращается время внеплановых простоев в случае утери или порчи данных.
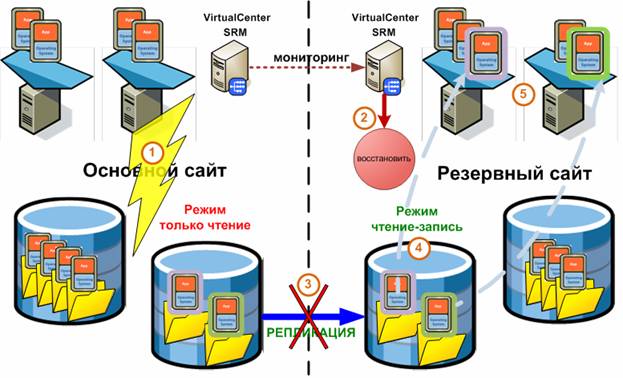
VMware Site Recovery Manager – обеспечение отказоустойчивости на уровне виртуального ЦОД. Самая критичная точка отказа в виртуальной инфраструктуре VMware – единая для всех хостов ESX система хранения. VMware Site Recovery Manager позволяет создать резервный ЦОД, содержащий в себе серверы, сетевые компоненты и систему хранения данных, которая в случае катастрофы на основном ЦОД, берет на себя функции по поддержке инфраструктуры виртуализации.
В случае использования SRM мы получаем следующие преимущества:
Устраняется единая точка отказа на уровне системы хранения за счет синхронной репликации дисков виртуальных машин на LUN другой системы хранения. В случае отказа происходит переключение на резервный дисковый массив.
Упрощается создание и тестирование планов аварийного восстановления в рамках предприятия (Disaster Recovery Plans). С помощью Site Recovery Manager можно создать тестовую инфраструктуру восстановления, запустить симуляцию катастрофы и посмотреть насколько быстро произойдет восстановление виртуальных машин. Все это можно сделать без ущерба для функционирующей производственной среды.
Простои в случае катастрофы к 0, естественно, не сводятся, но сокращаются в разы, или даже в десятки раз. Безусловно, имея резервные копии всех виртуальных машин, можно восстановить виртуальную инфраструктуру на другом оборудовании, но, во-первых, это займет значительно больше времени, а, во-вторых, обеспечит некоторую потерю данных.
Тем не менее, использование SRM не отменяет необходимость создание резервных копий виртуальных машин, поскольку утеря данных вследствие пользовательской ошибки приведет к утере данных и на резервном ЦОД.
Из всего перечисленного выше следует, что компания VMware покрыла своими продуктами почти все возможные точки отказа виртуальной инфраструктуры. Однако для обеспечения наиболее отказоустойчивой виртуальной инфраструктуры, потребуется приобретение не только продукта VMware Virtual Infrastructure, но и Site Recovery Manager (к которому нужна, конечно же, и резервная инфраструктура). Однако если ключевой фактор для вашей инфраструктуры – минимизация потерь вследствие непредвиденных сбоев и катастроф, выбор VMware среди продуктов виртуализации очевиден.

 RSS
RSS