VMware vCenter Converter – это классический инструмент VMware для перевода физических и виртуальных систем в формат виртуальных машин VMware. Его корни уходят к утилите VMware P2V Assistant, которая существовала в 2000-х годах для «Physical-to-Virtual» миграций. В 2007 году VMware выпустила первую версию Converter (3.0), заменив P2V Assistant...
Функция vSphere Configuration Profiles, впервые представленная в VMware vSphere 8.0, позволяет администраторам VMware Cloud Foundation управлять конфигурацией хостов ESX на уровне кластера. В данном материале рассматривается, чем эта функция отличается от Host Profiles, и как выполнить переход с Host Profiles на vSphere Configuration Profiles в vSphere 9.
Примечание: скриншоты и описанные шаги основаны на vSphere 9.0.2. В более ранних или более поздних версиях отдельные элементы интерфейса или формулировки могут отличаться.
О vSphere Configuration Profiles
vSphere Configuration Profiles — новая функция, впервые появившаяся в vSphere 8.0. Она является преемником Host Profiles в части управления конфигурацией хостов ESX в масштабе. Host Profiles неудобны тем, что требуют полного описания конфигурации хоста целиком. Это создаёт избыточную нагрузку на администраторов, которым, как правило, достаточно указать лишь те изменения, которые необходимо внести в конфигурацию.
vSphere Configuration Profiles, напротив, требует от администратора только определить отклонения от конфигурации по умолчанию. Это делает конфигурационный документ удобочитаемым и значительно более управляемым.
Переход с Host Profiles
Администраторы, управляющие конфигурацией хостов ESX с помощью Host Profiles в кластере, жизненный цикл которого управляется образами vSphere Lifecycle Manager, могут перевести кластеры на использование vSphere Configuration Profiles.
Примечание: использование vSphere Configuration Profiles с кластерами под управлением базовых уровней (baselines) поддерживается в vSphere 8 U3. Однако в vSphere 9 такие кластеры больше не поддерживаются, а Host Profiles считаются устаревшими, хотя и продолжают поддерживаться. Рекомендуется использовать кластеры под управлением образов vSphere Lifecycle Manager.
Перед переходом рекомендуется убедиться, что хосты ESX соответствуют текущему Host Profile. Ниже описан процесс перехода.
Управление конфигурацией на уровне кластера
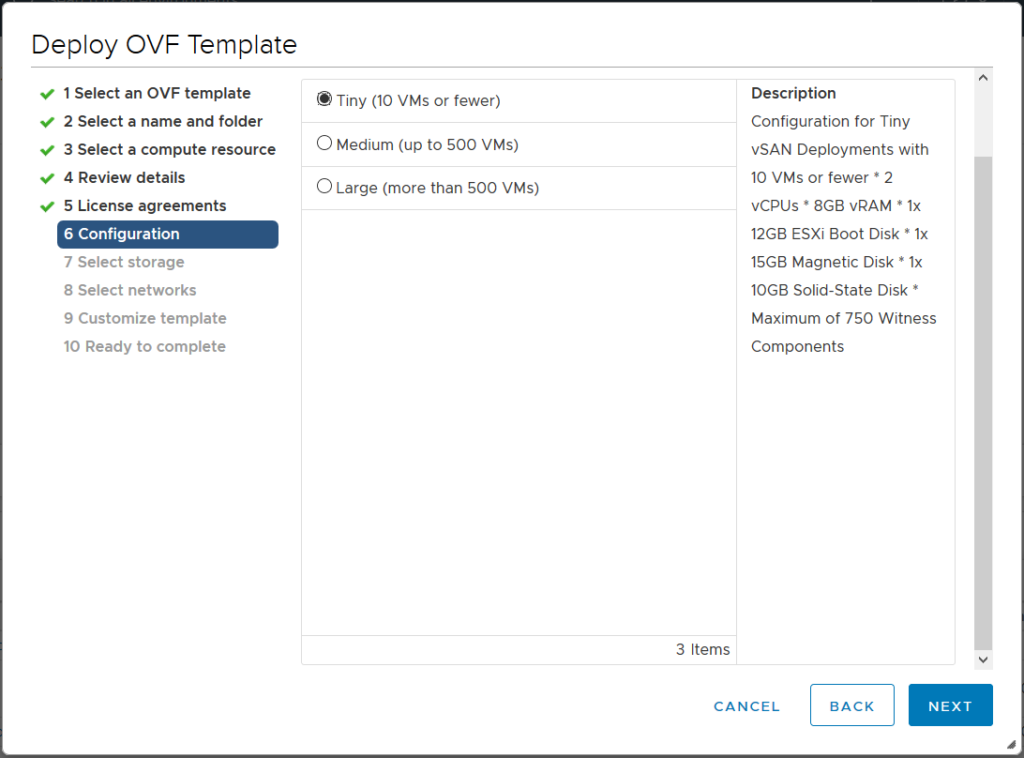
Первый шаг — включить vSphere Configuration Profiles в кластере. Для этого перейдите в Cluster > Configure > Configuration в разделе Desired State и нажмите Create Configuration. Будут запущены проверки совместимости, чтобы убедиться, что кластер может быть переведён на vSphere Configuration Profiles. На рисунке 1 показан вариант запуска vSphere Configuration Profiles в существующем кластере.
Примечание: если к кластеру прикреплён Host Profile, появится предупреждение о необходимости удалить его после завершения перехода. После перехода Host Profiles не могут быть прикреплены ни к кластеру, ни к хостам внутри него. Этот процесс можно использовать и в том случае, если Host Profiles в данный момент не применяются.
Создание конфигурации
Далее необходимо указать, каким образом конфигурация хоста ESX для vSphere Configuration Profiles должна быть импортирована. Доступны два варианта:
Импорт с эталонного хоста.
Импорт JSON-файла с желаемой конфигурацией кластера.
Поскольку выполняется переход кластера, управляемого с помощью Host Profiles, предпочтительным вариантом является IMPORT FROM REFERENCE HOST. В качестве эталонного хоста можно выбрать любой хост ESX в кластере — все хосты уже должны соответствовать используемому Host Profile.
Примечание: при импорте с эталонного хоста любые отклонения от его конфигурации будут зафиксированы как переопределения хоста. Возможно, потребуется вручную проверить конфигурацию и удалить эти переопределения, если необходима единая конфигурация для всех хостов кластера.
На рисунке 2 показаны варианты импорта. Нажмите Import.
На рисунке 3 показан выбор эталонного хоста.
После импорта нажмите Next. Процесс импорта проверяет сгенерированный документ относительно всех хостов ESX в кластере. После успешной проверки нажмите Next. На рисунке 4 показан этап проверки конфигурации.
Предварительная проверка и применение
На последнем шаге vSphere Configuration Profiles проверяет хосты ESX в кластере на соответствие желаемой конфигурации и устраняет любые отклонения, обнаруженные в ходе проверки.
Примечание: поскольку выполняется переход с кластера под управлением Host Profile, исправлений не ожидается. Ознакомьтесь с влиянием изменений конфигурации на хосты. Нажмите Finish and Apply. На рисунке 5 показан предварительный просмотр эффекта применения. Нажмите Continue.
После этого сгенерированный vSphere Configuration Profile будет установлен в качестве желаемой конфигурации кластера, а все несоответствующие хосты ESX будут приведены в соответствие. На рисунке 6 показан диалог подтверждения завершения и применения.
Функция vSphere Configuration Profiles теперь включена, и доступен просмотр заданных конфигураций. На рисунке 7 показано, что конфигурация на уровне кластера включена.
На рисунке 8 показано соответствие хостов конфигурации кластера.
На завершающем шаге необходимо отсоединить Host Profile от хостов ESX.
Итог
Управление конфигурациями ESX остаётся непростой задачей в корпоративных средах. vSphere Configuration Profiles — новая возможность, впервые представленная в vSphere 8.0, которая решает эту задачу в масштабе большой инфраструктуры.
На Cloud Field Day 25 команда VMware представила серию докладов о том, как VMware Cloud Foundation (VCF) решает критически важные задачи корпоративной инфраструктуры. Сессии продемонстрировали уникальные возможности VCF: устранение глобального дефицита памяти, доставку сетевых сервисов по образцу публичного облака в частных облачных средах и организацию самообслуживаемого выделения баз данных.
Многоуровневое кэширование памяти на NVMe
Первую сессию открыл Дейв Морера (Dave Morera), старший технический архитектор по маркетингу, с докладом о технологии Advanced NVMe Memory Tiering в VCF. Память является самым дорогостоящим и ограничивающим узким местом современных датацентров: она сдерживает плотность виртуальных машин и увеличивает совокупную стоимость владения.
Технология Advanced NVMe Memory Tiering решает эту задачу за счёт интеллектуальной интеграции на уровне гипервизора: она автоматически распределяет данные между высокопроизводительным и более экономичным уровнями памяти. Результаты говорят сами за себя: организации могут достичь снижения TCO более чем на 40%, одновременно повышая плотность виртуальных машин и эффективность потребления ресурсов. Ключевое преимущество VCF — бесшовная интеграция непосредственно на уровне гипервизора. Вместо того чтобы рассматривать память как фиксированное аппаратное ограничение, VCF превращает её в динамический стратегический ресурс, адаптирующийся к требованиям рабочих нагрузок в реальном времени.
База данных как услуга без узких мест
Эрик Грей (Eric Gray), главный архитектор по техническому маркетингу, показал, как VMware Data Services Manager (DSM) устраняет давнюю проблему — узкие места при выделении баз данных. Базы данных с открытым исходным кодом — PostgreSQL и MySQL — пользуются высоким спросом, однако традиционный процесс их предоставления порождает очереди заявок, пробелы в управлении и риски.
DSM обеспечивает предоставление баз данных как услуги (DBaaS) по требованию на платформе VMware Cloud Foundation. Расширенный сервис для VCF обеспечивает защищённое самообслуживаемое развёртывание баз данных при сохранении видимости и контроля через политики инфраструктуры и управление доступом на основе ролей (RBAC). Решение автоматизирует развёртывание высокодоступных конфигураций, реплик для чтения, резервное копирование и восстановление на момент времени. Это превращает операции второго дня из обременительной работы в автоматизированную возможность. С помощью DSM команды разработчиков получают необходимую им гибкость, тогда как инфраструктурные команды сохраняют управление и операционный контроль.
Сетевые сервисы с гибкостью облака
В завершающей сессии выступил Дмитрий Десмидт (Dimitri Desmidt), старший технический менеджер продукта NSX, с докладом о сетевых возможностях VCF. Цель доклада состояла в том, чтобы развеять распространённое заблуждение: будто возможности физических фабрик VXLAN устраняют необходимость в программно-определяемых сетях. Доклад «Почему VCF Networking (NSX) необходим — даже в мире VXLAN» обосновал, почему современные частные облака требуют большего, чем просто базовое оверлейное соединение.
VCF Networking (NSX) отделяет сеть от физической фабрики, обеспечивая автоматизированные сетевые сервисы, управляемые политиками, которые нативно интегрируются с vCenter и VCF Automation. Эта интеграция даёт операционную простоту, недостижимую только за счёт физических фабрик. Особого внимания заслуживают виртуальные частные облака (VPC): они позволяют разработчикам мгновенно выделять защищённые многопользовательские среды без глубоких знаний в области сетевых технологий. VCF Networking — это не просто оверлей, а базовый уровень, открывающий гибкость, операционную простоту и подлинные облачные операционные модели внутри современного датацентра.
Ценностное предложение VCF
Три сессии на Cloud Field Day 25 продемонстрировали единую тему: VMware Cloud Foundation предоставляет возможности, которые решают реальные корпоративные задачи с измеримыми бизнес-результатами. Снижение TCO на 40% и более за счёт интеллектуального многоуровневого кэширования памяти, устранение узких мест при выделении баз данных, обеспечение облачной гибкости в частной инфраструктуре — всё это делает VCF фундаментом современных корпоративных ИТ. Полные записи докладов доступны в плейлисте Cloud Field Day 25 на YouTube и предлагают техническую глубину по каждой из обсуждённых возможностей.
В какой-то момент требования к ресурсам для Witness VM в vSAN ESA исчезли из официальной документации. Между тем этот вопрос остаётся актуальным: сколько памяти выделяется виртуальной машине и сколько у неё vCPU? Ответ зависит от выбранного профиля — Witness VM доступна в трёх вариантах: M, L и XL.
Выбор профиля определяется количеством виртуальных машин, которые планируется развернуть. При этом рекомендуется закладывать запас на рост. Когда Witness VM разворачивается через мастер развёртывания, нужные цифры там не указаны — однако их можно узнать, заглянув в OVF-дескриптор.
Из OVF-файла vSAN ESA Witness получены следующие данные о ресурсах:
vSAN ESA Witness XL — 8 vCPU, 64 ГБ памяти
vSAN ESA Witness L — 4 vCPU, 32 ГБ памяти
vSAN ESA Witness M — 4 vCPU, 16 ГБ памяти
Для тех, кто использует vSAN OSA, требования к ресурсам следующие:
vSAN OSA Witness XL — 6 vCPU, 32 ГБ памяти
vSAN OSA Witness L — 2 vCPU, 32 ГБ памяти
vSAN OSA Witness Normal — 2 vCPU, 16 ГБ памяти
vSAN OSA Witness Tiny — 2 vCPU, 8 ГБ памяти
Важно учитывать, что приведённые значения актуальны на момент публикации — с выходом новых версий vSAN требования к ресурсам могут измениться.
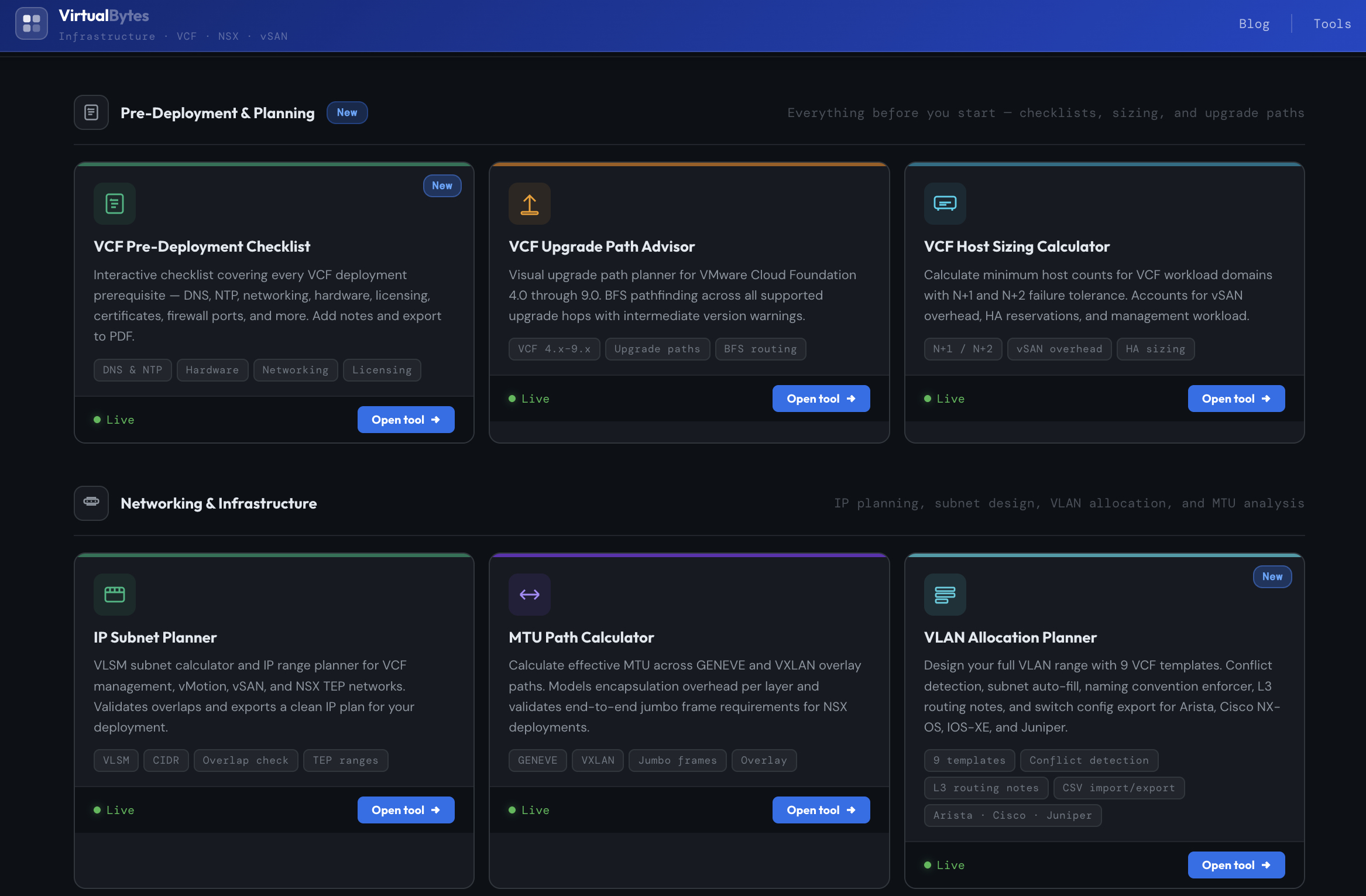
В сфере виртуализации и облачной инфраструктуры системные инженеры регулярно сталкиваются с задачами расчётов, проверки параметров конфигурации и подготовки инфраструктуры к развертыванию. Именно для таких задач создан сайт https://tools.virtualbytes.cloud/ — онлайн-площадка с полезными утилитами для специалистов по VMware-инфраструктуре и облачным платформам.
Что представляет собой сервис
Tools.VirtualBytes.Cloud — это коллекция веб-инструментов, предназначенных для работы с инфраструктурными компонентами VMware-экосистемы и сопутствующих технологий. Сервис позволяет использовать различные утилиты прямо в браузере без установки дополнительного программного обеспечения на локальную машину.
Основная идея платформы — предоставить инженерам быстрый доступ к вспомогательным инструментам, которые упрощают администрирование и проектирование виртуальной инфраструктуры.
Какие инструменты доступны онлайн
Сервис ориентирован на специалистов, работающих с современными датацентрами и программно-определяемыми инфраструктурами. Среди основных направлений инструментов:
Работа с платформой VMware Cloud Foundation (VCF)
Инструменты для VMware NSX и сетевой виртуализации
Вспомогательные утилиты для vSAN
Сетевые и инфраструктурные калькуляторы
Инструменты для анализа и подготовки конфигураций
Благодаря веб-формату инструменты можно использовать с любого устройства — достаточно открыть сайт в браузере.
Бесплатные онлайн-утилиты
VCF Pre-Deployment Checklist
Интерактивный чеклист, охватывающий все требования перед развертыванием VCF — DNS, NTP, сетевую инфраструктуру, оборудование, лицензии, сертификаты, порты файрвола и многое другое. Позволяет добавлять заметки и экспортировать результат в PDF.
VCF Upgrade Path Advisor
Визуальный планировщик путей обновления для VMware Cloud Foundation версий 4.0–9.0. Использует поиск оптимального пути (BFS) между поддерживаемыми этапами обновления и предупреждает о промежуточных версиях.
VCF Host Sizing Calculator
Калькулятор минимального количества хостов для доменов нагрузки VCF с учетом отказоустойчивости N+1 и N+2. Учитывает накладные расходы vSAN, резервации HA и нагрузку management-компонентов.
IP Subnet Planner
Калькулятор подсетей VLSM и планировщик диапазонов IP-адресов для сетей VCF: management, vMotion, vSAN и NSX TEP. Проверяет пересечения подсетей и позволяет экспортировать готовый IP-план для развертывания.
MTU Path Calculator
Калькулятор эффективного MTU для overlay-сетей GENEVE и VXLAN. Моделирует накладные расходы инкапсуляции на каждом уровне и проверяет требования к jumbo-фреймам для NSX-инфраструктуры.
VLAN Allocation Planner
Инструмент для проектирования полного диапазона VLAN с использованием 9 шаблонов VCF. Включает обнаружение конфликтов, автоматическое заполнение подсетей, контроль соглашений по именованию, заметки по L3-маршрутизации и экспорт конфигураций коммутаторов для Arista, Cisco NX-OS, IOS-XE и Juniper.
VCF 9 Network Config Generator
Генератор полной сетевой конфигурации для VCF 9, включая назначение VLAN, параметры MTU, политики teaming и конфигурацию пулов NSX TEP для развертываний с несколькими кластерами.
vSAN Capacity Calculator
Калькулятор полезной емкости vSAN для архитектур OSA и ESA с политиками RAID-1, RAID-5 и RAID-6. Учитывает slack space, отказ хостов и приблизительную эффективность дедупликации.
NSX Firewall Rule Planner
Инструмент для планирования и документирования правил распределенного файрвола NSX. Позволяет задавать группы источников и назначений, сервисы и область применения (Applied-To), проверяет логику правил и экспортирует их в структурированную таблицу.
VCF Day 2 Operations Planner
Набор пошаговых runbook-процедур для операций Day-2: расширение кластера, создание доменов нагрузки, ротация сертификатов, обновление компонентов, смена паролей, расширение vSAN и управление сегментами NSX.
Для кого предназначен сайт
Платформа будет полезна:
Системным администраторам и инженерам виртуализации
Архитекторам облачной инфраструктуры
DevOps-специалистам
Инженерам датацентров и лабораторий
Особенно ценным ресурс становится при работе с VMware-экосистемой, где часто требуется быстро рассчитать параметры инфраструктуры или проверить настройки перед развертыванием.
Итог
Tools.VirtualBytes.Cloud — это полезный ресурс для специалистов по виртуализации и облачным технологиям. Он объединяет набор практических инструментов, которые помогают упростить работу с инфраструктурой VMware и ускорить решение повседневных задач администрирования.
Для инженеров, работающих с VCF, NSX и другими компонентами программно-определяемого дата-центра, подобные сервисы позволяют экономить время и повышать эффективность управления инфраструктурой.
Сегодня мы рассмотрим вопросы о неизменяемости (immutability) в Kubernetes. На фоне новой волны интереса особенно заметно, что сообщество Kubernetes рассматривает эту тему с иной точки зрения, чем раньше. Пользователи меньше сосредоточены на неизменяемости на уровне отдельного узла и больше интересуются тем, как принципы неизменяемости применяются при управлении целым парком кластеров. Именно это является фундаментальной причиной существования проекта Cluster API.
Почему неизменяемость важна
Значимость неизменяемости проистекает из тех преимуществ, которые этот подход даёт приложениям, работающим поверх Kubernetes. Наиболее важные преимущества, которые пользователи Kubernetes получают благодаря неизменяемости, приведены ниже.
Скорость
В современной ИТ-среде скорость имеет первостепенное значение. Например, скорость необходима, когда нужно масштабировать инфраструктуру для обработки всплесков пользовательских запросов, она нужна при выполнении blue/green-развертываний или при масштабировании инфраструктуры вниз, чтобы держать под контролем стоимость приложений или освобождать ресурсы для других задач.
Скорость также критически важна при выполнении операций обслуживания, которые должны укладываться в ограниченное временное окно, или при реагировании на любые виды сбоев — от проблем с одним экземпляром приложения до ситуаций, когда выходит из строя целый регион.
Неизменяемость является фундаментальной основой для достижения скорости во всех этих сценариях и не только. Именно благодаря неизменяемости можно использовать инструменты, позволяющие за миллисекунды запускать десять идентичных Pod’ов, за секунды создавать новые клоны машин, на которых размещаются узлы Kubernetes, или за минуты поднимать новый полностью работоспособный кластер Kubernetes.
Операции в масштабе
С определённой точки зрения современные ИТ-операции находятся на пересечении масштаба и скорости. Неизменяемость крайне важна для решения подобных задач, потому что она создаёт основу для создания согласованных и доверенных клонов ваших Pod’ов, виртуальных машин и даже всего кластера Kubernetes.
Когда вы начинаете использовать такие доверенные клоны, появляется уверенность, что среды разработки, QA и production ведут себя одинаково. Без доверенных клонов вашей операционной команде придётся сталкиваться с дрейфом конфигураций, а «снежинки» (уникальные, неповторимые конфигурации хостов) плохо масштабируются.
Безопасность
Неизменяемость также часто связывают с безопасностью. Хотя это в целом верно, есть несколько уникальных преимуществ, которые неизменяемость даёт именно с точки зрения безопасности. При этом для некоторых аспектов безопасности существуют и другие достойные альтернативы, которые организации могут и должны рассматривать.
Например, одно из уникальных преимуществ — неизменяемость создаёт основу для построения систем, в которых базовые виртуальные машины являются эфемерными, поскольку они периодически пересоздаются «с нуля». Это создаёт движущуюся цель, значительно усложняя работу злоумышленников.
С другой стороны, например, неизменяемая операционная система может успешно использоваться для уменьшения поверхности атаки внутри виртуальной машины, но многие организации достигают той же цели с помощью AppArmor, SELinux, защищённых образов и других механизмов.
Продолжая тот же пример, процесс обновления A/B, характерный для неизменяемых ОС, также может иметь достойную и, возможно, более надёжную альтернативу — когда изменения разворачиваются путём создания новых машин и удаления старых. Результат тот же, но используются простые примитивы создания и удаления — такие же, какие Kubernetes применяет для Pod’ов.
Стабильность
Инженеры-разработчики те, кто поддерживает open source-проекты, постоянно сталкиваются с тем, что у любого проекта или системы есть ограниченный «бюджет сложности», который она может выдержать за определённое время. Когда этот бюджет исчерпывается, начинаются проблемы. Снижается качество, и становится сложно своевременно исправлять ошибки и уязвимости (CVE).
Неизменяемость значительно помогает справляться с этим бюджетом сложности. Она позволяет инженерам резко сократить количество переменных, которые нужно учитывать, например, при управлении жизненным циклом объектов вроде виртуальной машины, на которой работает узел Kubernetes. В результате системы, основанные на принципах неизменяемости, обычно обеспечивают более простую, стабильную и надёжную платформу для приложений. А стабильность и надёжность важны как сегодня, так и для долгосрочной устойчивости вашего технологического стека.
Как добиться неизменяемости в Kubernetes
В своей основе неизменяемость — это концепция, философия. Чтобы сделать её реальностью, нужны технологии, которые поддерживают этот подход. Kubernetes - отличная отправная точка: он предоставляет такие примитивы, как неизменяемые Pod’ы, а также более высокоуровневые абстракции - например Deployments и StatefulSet - для управления ими.
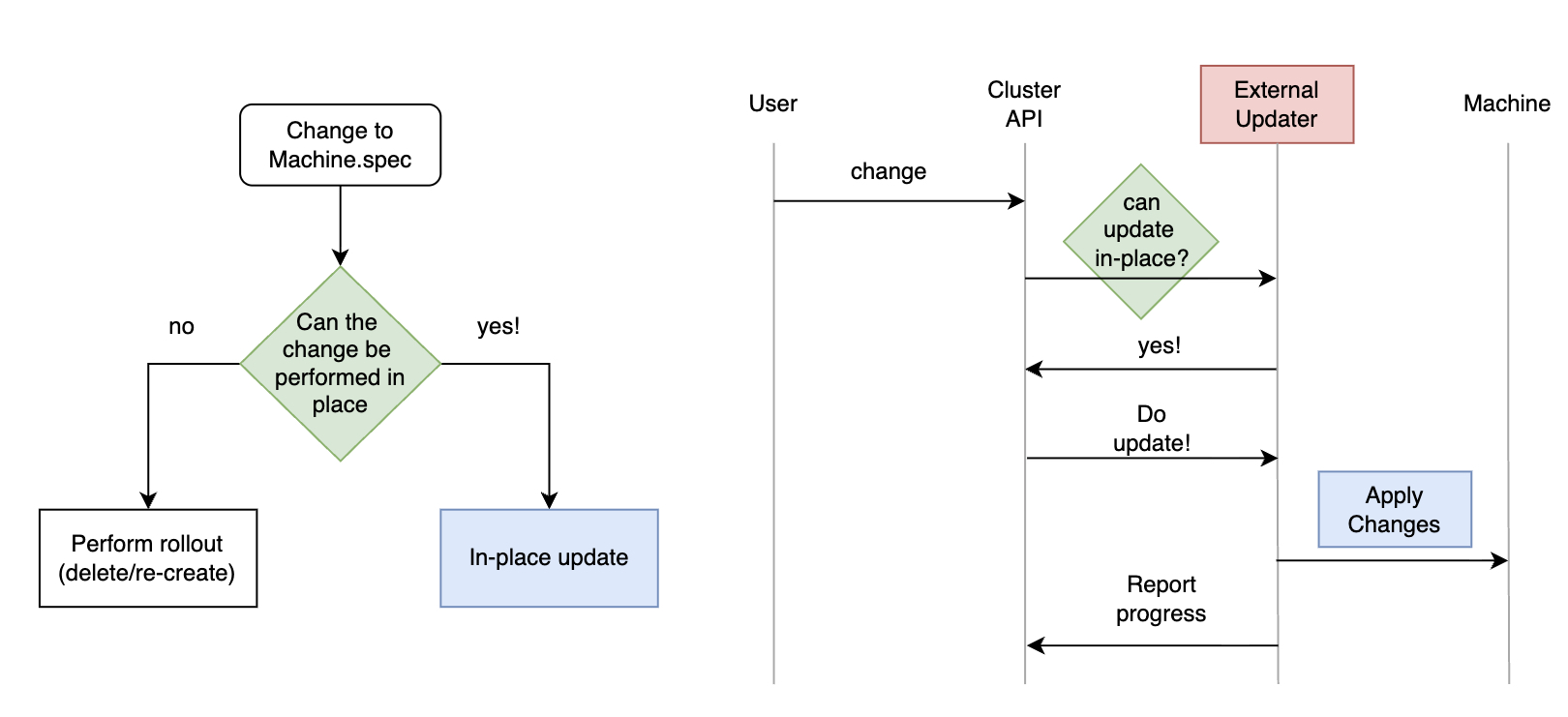
Однако Kubernetes не управляет базовой инфраструктурой. Именно здесь появляется Cluster API, поскольку один из фундаментальных принципов проекта — «Kubernetes на всех уровнях». Cluster API позволяет рассматривать Machine (элемент инфраструктуры, например виртуальную машину, на которой работает узел Kubernetes) как неизменяемый компонент.
Когда требуется изменение, вместо модификации существующей машины Cluster API создаёт новую и удаляет старую — аналогично тому, как Kubernetes заменяет Pod’ы. Предоставляя абстракции для управления группами машин, такие как KubeadmControlPlane и MachineDeployment, Cluster API позволяет усиливать преимущества неизменяемости при управлении целым кластером или даже парком кластеров.
Если вы хорошо знакомы с Cluster API, вы можете заметить, что здесь есть серая зона — операционная система, установленная на машине, управляемой CAPI. Cluster API не занимает жёсткой позиции относительно операционной системы на машине, потому что, как показал опыт последних лет, именно здесь разные организации и продукты могут и должны применять разные подходы.
Во-первых, у каждой организации есть собственные предпочтения относительно используемой ОС и допустимых компромиссов на уровне операционной системы. Во-вторых, многие организации не хотят вводить особый подход к операционной системе машин в кластере Kubernetes. Они предпочитают иметь одну поддерживаемую ОС и использовать её на разных платформах и для разных типов приложений — и чаще всего это не неизменяемая ОС.
Ключом к работе с такими различными требованиями и технологиями являются многочисленные точки расширения Cluster API. Используя эти точки расширения, теперь можно выполнять тщательно проверенный набор операций обновления «на месте» безопасным и полностью автоматизированным способом.
Несколько примеров
Пошаговые обновления (rolling upgrades)
Вместо выполнения сложных процедур обновления существующих машин Cluster API проводит rollout, при котором создаются новые «чистые» машины для замены старых. Этот подход, основанный на принципах неизменяемости, позволяет не только выполнять обновления Kubernetes, но и вносить любые изменения в машины (инфраструктура, ОС и компоненты Kubernetes), используя два простых примитива: создание и удаление Machine.
Процесс по своей природе повторяем и предсказуем; замена каждой машины гарантирует, что каждый узел достигнет желаемого состояния без сюрпризов, часто вызванных конфигурационным дрейфом. Это просто, надёжно, быстро и безопасно.
Кроме того, Cluster API гарантирует соблюдение требований к доступности во время rollout. Он также поддерживает цепочные обновления Kubernetes через несколько минорных версий, а рабочие узлы могут пропускать промежуточные минорные версии, если это допускается политикой version skew Kubernetes.
Восстановление нездоровых машин
Как поступить с машинами, которые постоянно работают некорректно — например, когда узел Kubernetes, размещённый на машине, сообщает состояние Ready = false более пяти минут? Cluster API позволяет определить MachineHealthChecks для обработки таких случаев. Когда запускается автоматическое восстановление, система использует принцип неизменяемости для быстрого и эффективного решения проблемы: быстро создаётся новая «чистая» машина-замена, а старая удаляется — снова используя те же два простых примитива: создание и удаление Machine.
Избегание ненужных rollout’ов
Машины — сложные компоненты, и иногда требуется внести изменения, которые не требуют drain узла или перезапуска Pod’ов; например, изменение сертификата реестра образов.
Если по какой-то причине вы хотите выполнить такие изменения без полного rollout машины, Cluster API предоставляет точки расширения, позволяющие выполнить тщательно проверенный набор обновлений «на месте» безопасным и полностью автоматизированным способом. Даже в этих случаях конфигурационный дрейф предотвращается за счёт одинакового применения изменений ко всем машинам.
Тот же пользовательский опыт, неизменяемость и лучшие стороны изменяемой инфраструктуры — всё под строгим контролем.
Итоги
Неизменяемость лежит в основе многих cloud-native систем, поскольку она обеспечивает скорость, масштабируемость операций и более сильные практики безопасности. В то же время сочетание неизменяемой инфраструктуры с тщательно контролируемыми изменяемыми операциями позволяет организациям использовать и другие проверенные операционные подходы там, где это уместно.
Именно этот баланс между неизменяемой и изменяемой инфраструктурой позволяет командам достигать скорости, безопасности и надёжности при управлении Kubernetes в большом масштабе.
В последнем выпуске подкаста Virtually Speaking Ли Ховард, руководитель IAM Product Management в Broadcom, рассказал, как Identity Security для VMware Cloud Foundation (VCF) обеспечивает безопасный, масштабируемый доступ с нулевым доверием в современных средах частного облака.
Этот выпуск является частью серии VCF Advanced Services, где освещаются возможности, усиливающие безопасность, соответствие требованиям и операционный контроль сверх базовой инфраструктуры.
В этом видео объясняется, почему идентификация больше не может рассматриваться как дополнительная функция безопасности. В мире Kubernetes-нагрузок, приложений, управляемых через API, систем AI и требований суверенных облаков идентификация должна быть фундаментальной.
От статической аутентификации к Zero Trust
Традиционные стратегии управления идентификацией строились вокруг служб каталогов, статических политик и базового единого входа. Эта модель работала, когда приложения были централизованы, а пользователи действовали в пределах определённых сетевых границ. Современное частное облако устроено иначе.
Пользователи распределены. Приложения контейнеризированы. Сервисы аутентифицируются друг перед другом. AI-агенты и платформы автоматизации действуют самостоятельно. В такой среде идентификация должна быть непрерывной, контекстной и учитывающей риски.
Архитектура нулевого доверия оценивает не только то, кто входит в систему, но и как, откуда и к чему именно пытается получить доступ. Безопасность идентификации становится динамической, адаптируясь к поведенческим сигналам, уровням привилегий и контексту среды. Именно здесь современные возможности IAM и PAM становятся критически важными.
IAM и PAM в VMware Cloud Foundation
Identity and Access Management (IAM) управляет аутентификацией, авторизацией и федерацией, используя такие стандарты, как SAML и OpenID Connect. В частном облаке, построенном на VMware Cloud Foundation, IAM должен быть управляемым через API и дружественным к DevOps, позволяя командам разработки интегрировать идентификацию в современные рабочие процессы без жёстких проприетарных ограничений.
Privileged Access Management (PAM) защищает наиболее чувствительный уровень среды: административный доступ и доступ уровня root. PAM обеспечивает доступ с минимально необходимыми привилегиями, хранит учётные данные в защищённых хранилищах, автоматически ротирует пароли и записывает привилегированные сессии. Это снижает риск внутренних угроз, злоупотребления учётными данными и горизонтального перемещения во время взлома.
Важно, что безопасность идентификации теперь распространяется не только на человеческих администраторов. Машинные идентификаторы, сервисные аккаунты и системы автоматизации также должны находиться под управлением. По мере роста Kubernetes-нагрузок и AI-систем управление секретами и доступом нечеловеческих субъектов становится столь же важным, как и управление входом пользователей.
Нативная для Kubernetes идентификация в частном облаке
Платформа Identity Security работает на Kubernetes внутри VMware Cloud Foundation. Такая облачно-нативная архитектура обеспечивает быстрое развертывание, автоматическое масштабирование при всплесках аутентификации и обновления без простоев.
Сервисы идентификации являются критически важными. Если аутентификация не работает, не работает ничего. Архитектура на базе Kubernetes обеспечивает устойчивость и операционную эффективность, одновременно устраняя необходимость избыточного резервирования ресурсов, характерную для устаревших систем идентификации.
Идентификация как ключевая возможность платформы
По мере того как организации пересматривают размещение нагрузок, требования суверенности и стратегии внедрения AI, идентификация становится центральным элементом архитектуры частного облака. Она должна поддерживать доступ по модели нулевого доверия, соответствие нормативным требованиям, управление машинными идентификациями и единый контроль в разных средах.
Безопасность идентификации больше не ограничивается входом в систему. Речь идёт о контроле доступа повсюду — для пользователей, приложений, сервисов и данных. И в современной среде VMware Cloud Foundation она встроена непосредственно в саму платформу.
Что дальше в серии роликов?
Этот выпуск является частью продолжающейся серии Virtually Speaking, посвящённой Advanced Services, доступным в VMware Cloud Foundation. В каждом выпуске специалисты VMware подробнее рассматривают конкретный сервис и практические результаты, которые он обеспечивает, вместе с людьми, которые ежедневно создают и внедряют эти решения.
В следующих выпусках будут освещаться сервисы, расширяющие возможности VCF за пределы базовой инфраструктуры, включая такие области, как продвинутые сети, безопасность, сервисы данных, наблюдаемость и AI. Цель этих роликов — показать, как эти возможности работают вместе, помогая организациям модернизировать инфраструктуру, защищать приложения и ускорять инновации.
Поскольку организации уделяют приоритетное внимание цифровой трансформации, они запускают смешанный набор приложений, используя как виртуальные машины, так и контейнеры для удовлетворения своих развивающихся инфраструктурных потребностей. Однако управление как традиционными, так и контейнерными приложениями создаёт сложность, операционную неэффективность и риски безопасности. Организациям необходима единая, упрощённая и безопасная платформа, которая соединит устаревшие и современные ИТ-среды.
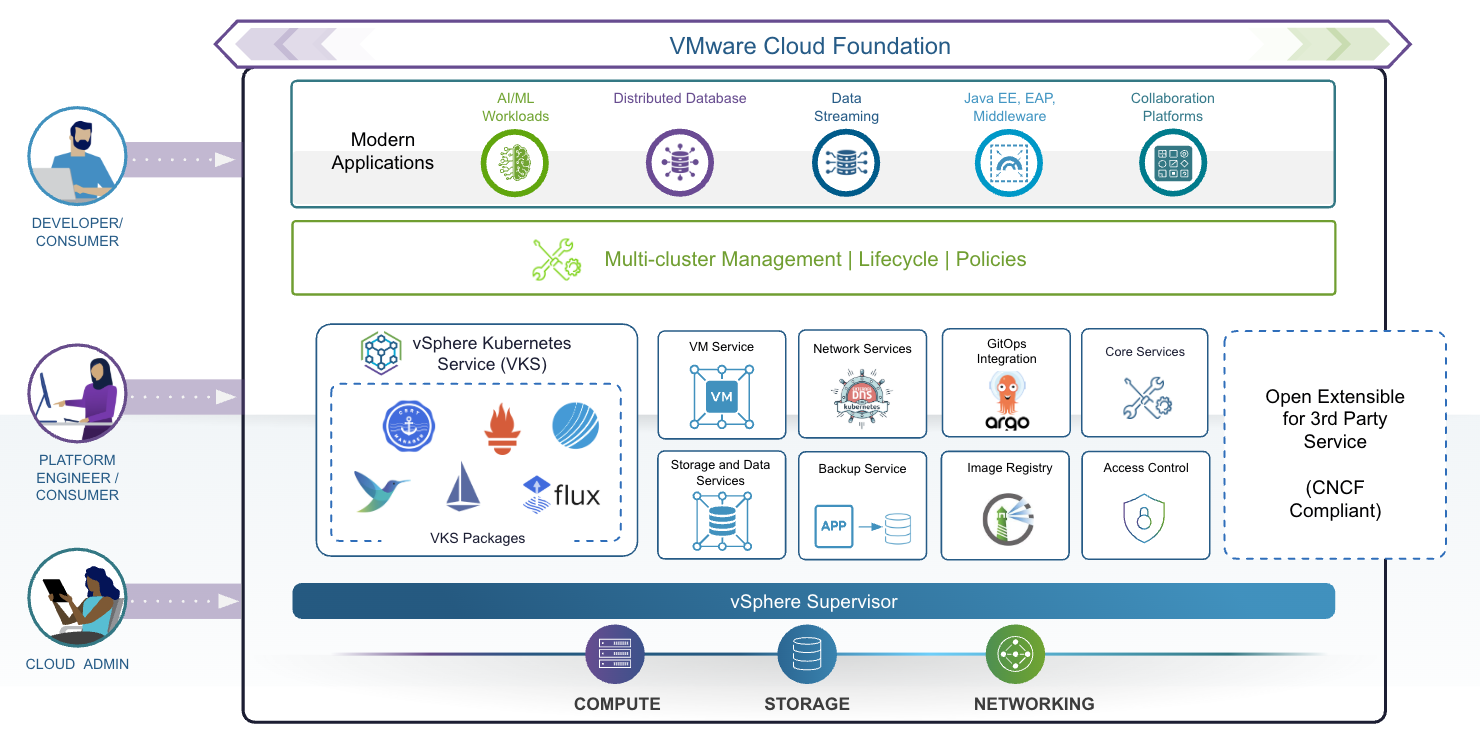
VMware Cloud Foundation (VCF) предлагает решение — VCF предоставляет единую платформу со встроенной средой выполнения Kubernetes, которая оркестрирует управление Kubernetes, позволяя предприятиям запускать современные приложения наряду с традиционными рабочими нагрузками, а также включает сертифицированный дистрибутив Kubernetes, соответствующий upstream-стандартам. С помощью vSphere Supervisor VCF предоставляет пользователям доступ к самообслуживанию для полного набора облачных сервисов «из коробки». Это работает в составе VMware vSphere Kubernetes Service (VKS), который используется для развертывания кластеров Kubernetes и включает совместимый выпуск Kubernetes, а также стандартный пакет ключевых компонентов OSS. VCF предоставляет облачным администраторам и платформенным инженерам выбор интерфейсов, включая GUI, CLI и API, что позволяет командам работать эффективно и продуктивно, вместо того чтобы тратить время на изучение новых наборов инструментов.
VMware недавно представила ключевые улучшения в работе Kubernetes на VCF 9.0. Независимо от того, модернизируете ли вы устаревшие приложения или масштабируете современные рабочие нагрузки, VCF 9.0 предлагает единую платформу для создания и эксплуатации всех ваших рабочих нагрузок в большом масштабе — безопасно и эффективно.
Единая платформа для виртуальных машин и контейнеров
VCF предоставляет единую платформу, которая поддерживает как устаревшие, так и современные рабочие нагрузки. Это позволяет организациям модернизировать все рабочие нагрузки единообразным способом с использованием последних инноваций Kubernetes.
Единый API для развёртывания и управления виртуальными машинами и контейнерами: единый API позволяет пользователям создавать, развёртывать и управлять как виртуальными машинами, так и кластерами Kubernetes. Это упрощает автоматизацию, снижает сложности интеграции и обеспечивает единые политики и средства безопасности для всех рабочих нагрузок. Благодаря единому API платформенные инженеры могут взаимодействовать с вычислительными ресурсами единообразно, устраняя необходимость в отдельных инструментах и снижая затраты на обучение.
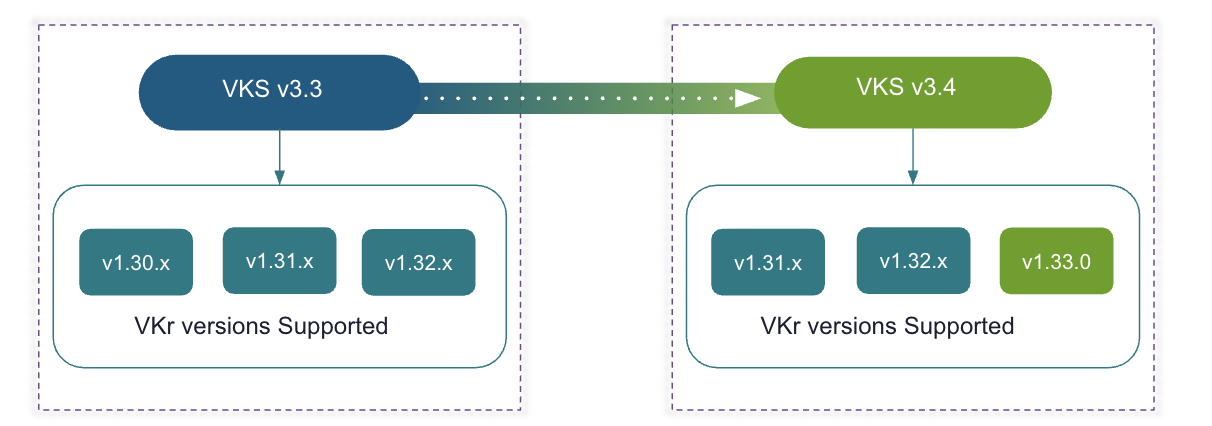
Сертифицированный релиз Kubernetes, соответствующий upstream, с независимой возможностью обновления: VCF использует полностью соответствующий upstream-дистрибутив Kubernetes, сертифицированный Cloud Native Computing Foundation (CNCF). Эта сертификация подтверждает, что реализация Kubernetes в vSphere соответствует программе Kubernetes Conformance Program, которая проверяет upstream API Kubernetes, рабочие нагрузки и инструменты экосистемы. Например, после обновления до VKS 3.4 вы сможете создавать и управлять кластерами Kubernetes с использованием последнего релиза vSphere Kubernetes 1.33, синхронизированного с последним релизом сообщества.
Поддержка N-2 версий Kubernetes для гибкого развертывания: VKS поддерживает текущий релиз Kubernetes и две предыдущие основные версии. Это означает, что VKS обеспечивает совместимость сразу с тремя версиями Kubernetes в любой момент времени, что позволяет различным корпоративным командам использовать ту версию, которая необходима их приложениям, а также иметь контроль и гибкость для обновления в собственном темпе.
Упрощённые и эффективные операции
VCF снижает операционную сложность, повышает гибкость управления и позволяет командам оптимизировать распределение ресурсов между различными средами.
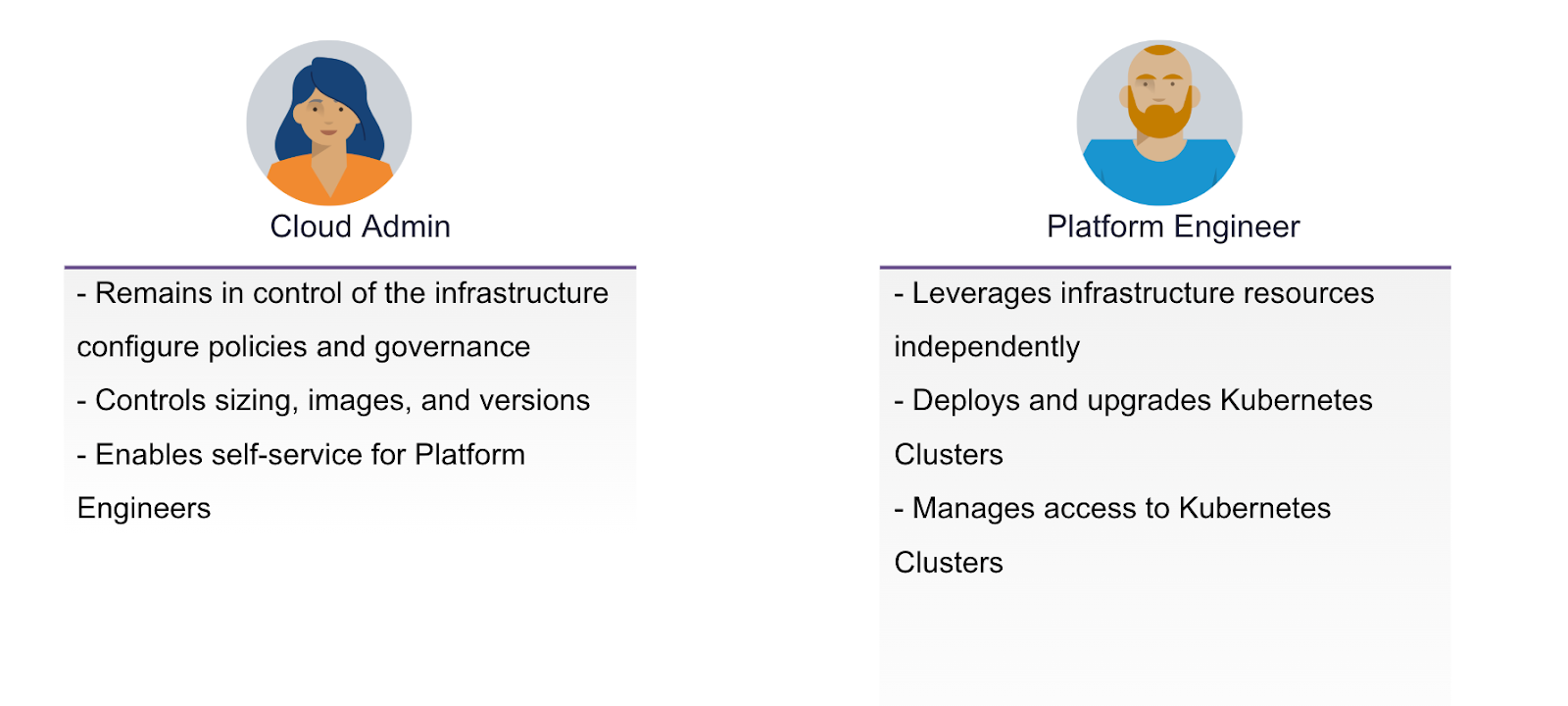
Самообслуживание для доступа к облачным сервисам с управлением и контролем: благодаря модели доступа на основе ролей платформенные инженеры могут использовать возможности самообслуживания для выделения инфраструктурных ресурсов (вычислительные, хранилища и сети) и набора расширенных облачных сервисов в vSphere Supervisor, таких как VM Service, Network Services и Image Registry, по требованию, в то время как облачные администраторы сохраняют управление и контроль с помощью политик и квот ресурсов. Доступ по модели самообслуживания также поддерживает multi-tenancy с изолированными средами для разных команд и проектов.
Независимое обновление vSphere Supervisor: VMware Cloud Foundation 9.0 предоставляет облачным администраторам дополнительную гибкость, позволяя обновлять vSphere Supervisor независимо от обновления vCenter. Благодаря асинхронным обновлениям снижается операционная сложность и обеспечивается большая гибкость для ИТ-команд в поддержании актуальности сред Kubernetes при сохранении стабильности всей инфраструктуры.
Автомасштабирование кластеров Kubernetes: улучшения автомасштабирования позволяют динамически изменять количество рабочих узлов на основе метрик в реальном времени, обеспечивая как производительность, так и эффективность. Благодаря поддержке возможностей scale-down-to-zero и scale-up-from-zero кластеры могут автоматически уменьшаться до нуля рабочих узлов в периоды простоя и бесшовно масштабироваться вверх при возобновлении нагрузки. Такая масштабируемость по требованию оптимизирует использование инфраструктуры, снижает операционные затраты и обеспечивает выделение ресурсов только тогда, когда это необходимо.
Workload zones для оптимизации распределения ресурсов: VCF 9.0 вводит повышенную гибкость благодаря зонам рабочих нагрузок (workload zones), позволяя облачным администраторам определять и управлять ими независимо, чтобы лучше согласовывать инфраструктурные ресурсы с требованиями рабочих нагрузок. vSphere Namespaces поддерживают как однозонные, так и многозонные конфигурации, что упрощает удовлетворение различных требований высокой доступности и сценариев аварийного восстановления. Облачные администраторы также могут расширять инфраструктуру частного облака, добавляя специализированные зоны, например выделяя ресурсы для нагрузок с интенсивным использованием GPU, что обеспечивает больший контроль, оптимизированное использование ресурсов и повышенную гибкость для различных развертываний.
Интеграция управления кластерами VKS: управление кластерами VKS позволяет облачным администраторам эффективно управлять кластерами и группами кластеров в различных средах. Благодаря встроенным возможностям, таким как управление несколькими кластерами на уровне всей инфраструктуры (fleet-wide multicluster management) и детализированный контроль доступа, команды могут ускорить развертывание, снизить операционную сложность и обеспечить единообразную конфигурацию. Такой унифицированный подход упрощает операции Day 2 и усиливает управление и контроль всей инфраструктуры Kubernetes.
Повышенная безопасность
VCF интегрирует встроенные функции безопасности для последовательной защиты рабочих нагрузок, что позволяет организациям снижать риски и улучшать общий уровень безопасности.
Встроенная высокая доступность и надежность: VCF обеспечивает встроенную высокую доступность и надежность не только для виртуальных машин, но и для современных рабочих нагрузок. Благодаря интеграции VKS, VCF гарантирует, что контейнеризированные приложения получают те же возможности корпоративного уровня по обеспечению отказоустойчивости, такие как vSphere HA. vSAN предоставляет политики постоянного хранения, адаптированные для stateful-нагрузок Kubernetes, а NSX обеспечивает сетевую доступность и безопасное соединение между кластерами. Благодаря унифицированному управлению жизненным циклом VCF поддерживает стабильное время безотказной работы и операционную устойчивость как для виртуальных машин, так и для контейнеров, работающих на надежной инфраструктуре.
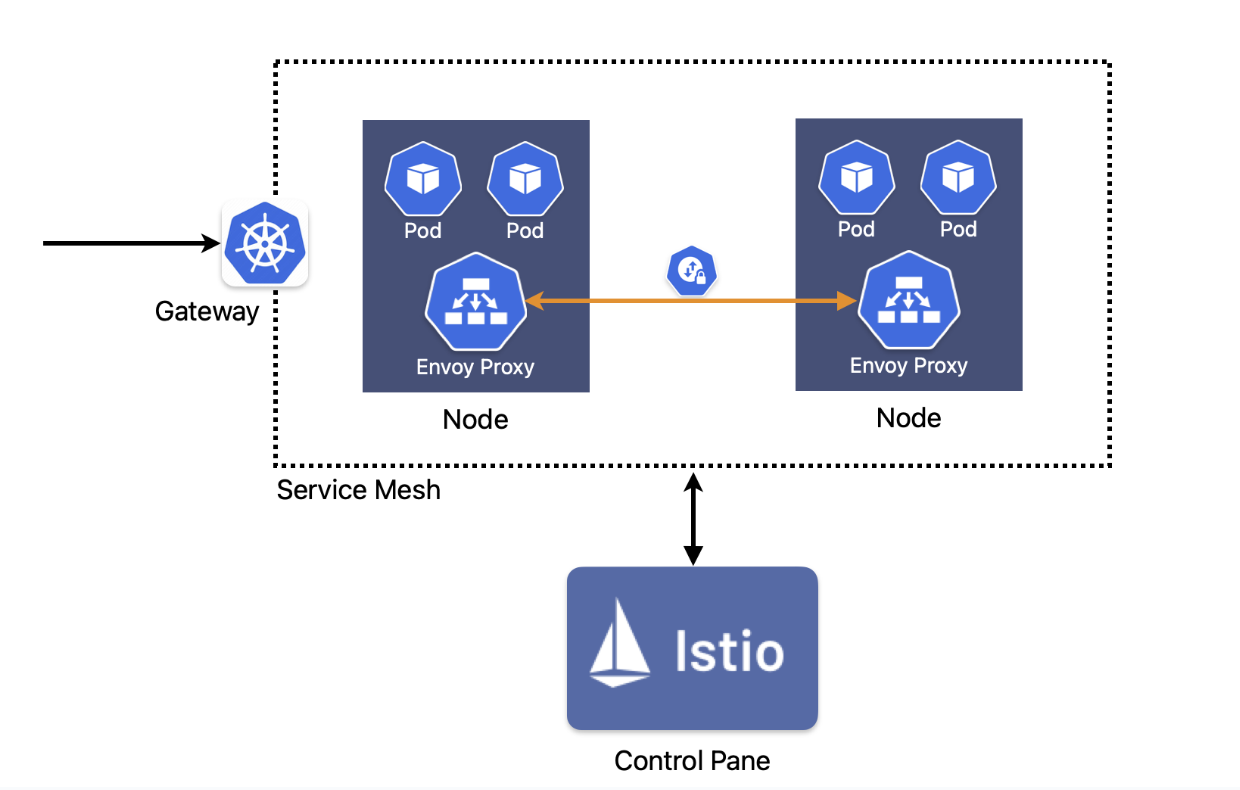
Интеграция Istio Service Mesh: предоставляет расширенные возможности, такие как обнаружение сервисов, безопасное взаимодействие сервисов друг с другом, маршрутизация трафика и балансировка нагрузки, а также применение политик через интегрированные инструменты наблюдаемости. Благодаря таким функциям, как ingress и egress шлюзы, внедрение сбоев (fault injection), ограничение скорости запросов (rate limiting) и поддержка архитектуры нулевого доверия (zero-trust), Istio Service Mesh позволяет платформенным командам управлять сложными средами микросервисов с прозрачностью, отказоустойчивостью и соответствием требованиям, одновременно упрощая операционные процессы между кластерами Kubernetes.
Режим OS FIPS для соответствия требованиям: новая опция конфигурации добавляет поддержку включения режима FIPS на уровне операционной системы, обеспечивая использование только криптографических модулей, прошедших валидацию FIPS, для соответствия строгим требованиям безопасности и комплаенса. Это улучшение даёт облачным администраторам гибкость в применении режима FIPS как для Linux, так и для Windows кластеров рабочих нагрузок, приводя среды Kubernetes в соответствие с федеральными и отраслевыми стандартами безопасности при сохранении операционного контроля над уровнем безопасности.
Расширенная поддержка: в дальнейшем VMware планирует предоставлять Extended Support для определённых версий релизов vSphere Kubernetes (VKr), делая поддержку доступной в течение 24 месяцев с момента GA. Это позволит клиентам VCF оставаться на одной минорной версии Kubernetes значительно дольше, если это необходимо. Первым релизом с расширенной поддержкой станет VKr 1.33.
Кроме этого, что еще делает VCF таким особенным для запуска контейнеризированных рабочих нагрузок? VCF делает контейнеры полноценными участниками инфраструктуры наравне с виртуальными машинами, глубоко интегрируя Kubernetes в основной стек инфраструктуры с единым управлением жизненным циклом и рассматривая контейнеризированные рабочие нагрузки с тем же операционным приоритетом, управляемостью и функциональностью, что и виртуальные машины. В VCF контейнеры запускаются внутри виртуальных машин. Такая архитектура повышает безопасность за счёт дополнительного сильного уровня изоляции между рабочими нагрузками, при этом позволяя предприятиям применять существующие инструменты безопасности, политики соответствия требованиям и контроль доступа ко всем рабочим нагрузкам.
В марте на российском рынке виртуализации серверов заметно усилился акцент на экосистемной совместимости, защищённой инфраструктуре и связке отечественного ПО с локальными аппаратными платформами. Ниже — обзор ключевых событий месяца.
Совместимость zVirt с системой доверенной загрузки «Соболь»
Одной из самых заметных мартовских новостей стало подтверждение совместимости платформы виртуализации zVirt с системой доверенной загрузки «Соболь». Для рынка это не просто технический тест, а важный сигнал о том, что отечественные платформы виртуализации всё активнее встраиваются в контур защищённой ИТ-инфраструктуры.
Практическое значение новости заключается в том, что организации из госсектора, критической инфраструктуры и компаний с повышенными требованиями к безопасности получают более предсказуемый сценарий внедрения виртуализации. Защита на этапе загрузки сервера дополняет архитектуру гипервизора и снижает риски компрометации базового уровня инфраструктуры.
В более широком контексте эта новость показывает зрелость экосистемы вокруг российских платформ виртуализации: заказчику уже недостаточно просто гипервизора, ему нужен связанный стек из виртуализации, средств защиты и поддержки регуляторных требований.
Sharx Base расширяет аппаратную совместимость через интеграцию с серверами Trinity
Другой важный сюжет марта связан с платформой Sharx Base и её совместимостью с серверами Trinity. Подобные новости на первый взгляд могут выглядеть как обычные интеграционные объявления, но для рынка импортозамещения они имеют стратегическое значение.
Сегодня заказчику нужен не отдельный программный продукт, а работоспособный и подтверждённый стек: сервер, слой виртуализации, система хранения и понятная схема поддержки. Именно поэтому новости о сертифицированной или подтверждённой совместимости привлекают внимание значительно сильнее, чем просто функциональные обновления.
Интеграция Sharx Base с серверами Trinity показывает, что российские игроки продолжают выстраивать полноценную инфраструктурную экосистему. Это снижает барьер входа для корпоративных клиентов и делает проекты миграции с зарубежных решений менее рискованными.
Реальные внедрения: использование Helius в крупной корпоративной инфраструктуре
Сильный информационный эффект в марте дали новости о практическом внедрении российских решений виртуализации в крупных инфраструктурных проектах. В этом контексте особое внимание привлекло использование Helius в составе геораспределённого вычислительного кластера у НМТП.
Такие кейсы важны потому, что рынок виртуализации давно вышел из стадии обсуждения возможностей на уровне презентаций. Для корпоративных заказчиков решающим аргументом становится подтверждение того, что отечественная платформа выдерживает промышленную эксплуатацию, масштабирование и работу в распределённой среде.
Появление подобных внедрений усиливает доверие к российским продуктам и служит сигналом для компаний, которые ещё находятся в фазе выбора альтернатив зарубежным платформам. Чем больше примеров работающих production-сценариев, тем быстрее ускоряется принятие решений на рынке.
Новые серверные платформы как фундамент для роста виртуализации
Мартовская повестка была связана не только с самим ПО виртуализации, но и с аппаратной базой, на которой эти решения будут массово разворачиваться. В этом смысле важной стала новость о включении серверов «Гравитон» в реестр Минпромторга.
Для сегмента виртуализации такие новости имеют прикладное значение. Массовое внедрение гипервизоров невозможно без понятной и доступной аппаратной платформы, которая подходит для корпоративных и государственных проектов, закупается по формальным требованиям и имеет прогнозируемый цикл поставки и поддержки.
Чем увереннее развивается российская серверная база, тем устойчивее выглядит вся экосистема виртуализации. Рынок постепенно переходит от точечных проектов к сборке полноценного импортонезависимого контура, где и программная, и аппаратная части развиваются синхронно.
Отраслевые конференции как индикатор зрелости рынка
Отдельным маркером зрелости рынка стала подготовка и проведение отраслевого мероприятия "Платформы виртуализации 2026", посвящённого российским платформам виртуализации, которое пройдет 31 марта 2026 года. Конференции в этой сфере уже выступают не витриной отдельных поставщиков, а пространством для обсуждения миграционных стратегий, реальных кейсов и динамики спроса.
Многие VMware-инфраструктуры сегодня находятся в переходной стадии: организации продолжают использовать
vSphere-кластеры, но постепенно переходят к модели Software-Defined Data Center и частного облака на базе VMware Cloud Foundation (VCF).
Полностью перестраивать инфраструктуру с нуля в производственной среде обычно невозможно. Там уже работают
десятки или сотни виртуальных машин, поэтому перенос на новую платформу должен происходить максимально
аккуратно. Именно для таких сценариев VMware предлагает механизм Brownfield-интеграции.
Этот подход позволяет смигрировать существующую инфраструктуру vSphere на VMware Cloud Foundation без
переустановки среды и без миграции виртуальных машин. Подробно этот процесс рассмотрел Tarsio Moraes в своем видео:
Что такое Brownfield-апгрейд
Brownfield-подход означает интеграцию уже существующей инфраструктуры в новую платформу без полного
развертывания новой среды.
В VMware-экосистеме это означает, что существующий vCenter Server,
кластеры ESX и запущенные виртуальные машины могут быть импортированы
в VCF как отдельный Workload Domain.
Таким образом инфраструктура сохраняет текущие рабочие нагрузки, но получает централизованное управление,
автоматизированное lifecycle-обновление и интеграцию сетевой платформы NSX.
Архитектура до и после интеграции
Исходная инфраструктура
Типичная среда включает vSphere 8, один или несколько кластеров ESXi,
vCenter Server и систему хранения — например vSAN или внешние датасторы.
Сетевая конфигурация обычно построена на распределенном коммутаторе Distributed Switch.
В такой архитектуре управление вычислениями, сетью и мониторингом может
осуществляться через разные инструменты.
После интеграции в VCF
После импорта инфраструктура становится частью платформы VMware Cloud Foundation.
Появляется централизованное управление через компоненты VCF, а инфраструктура
разделяется на management domain и workload domains.
Также стоит учитывать изменения в продуктовой линейке VMware:
многие функции бывшей линейки Aria теперь встроены непосредственно в VMware Cloud Foundation (как функционал модуля Operations).
Подготовка инфраструктуры
Перед запуском Brownfield-апгрейда необходимо убедиться,
что инфраструктура соответствует требованиям совместимости.
В первую очередь проверяются версии компонентов:
vSphere, vCenter Server и ESXi (теперь он снова называется ESX). Кроме того,
важно убедиться в совместимости оборудования через VMware Compatibility Guide.
Также необходимо проверить базовые инфраструктурные сервисы:
DNS, NTP, доступность сетей управления и состояние датасторов.
Особенно важно убедиться, что DNS корректно разрешает имена
хостов ESX, vCenter и будущих узлов NSX Manager.
Подготовка среды управления
Перед импортом vSphere-среды необходимо подготовить управляющие компоненты VMware Cloud Foundation.
К ним относятся VCF Fleet Management и VCF Operations.
Эти сервисы отвечают за централизованное управление инфраструктурой,
мониторинг и lifecycle-операции.
На этом этапе стоит проверить доступность management-компонентов,
валидность сертификатов и сетевую связность между сервисами управления и vCenter.
Использование VCF Import Tool
Для интеграции существующей среды используется специальный инструмент —
VCF Import Tool.
Он анализирует конфигурацию vSphere,
выполняет проверку совместимости и подготавливает инфраструктуру к импорту.
Перед запуском процесса выполняется серия pre-check проверок,
которые анализируют сеть, лицензии, сертификаты, конфигурацию кластеров
и параметры хранения.
Если обнаружены ошибки или предупреждения, их необходимо устранить
до начала импорта.
Импорт vCenter как Workload Domain
После завершения подготовительных этапов можно приступать к импорту
существующего vCenter.
В интерфейсе VCF создаётся новый workload domain,
после чего указываются параметры подключения к существующему vCenter.
После проверки параметров запускается автоматический рабочий процесс (workflow),
который выполняет регистрацию vCenter в инфраструктуре VCF.
С этого момента среда становится частью VMware Cloud Foundation.
Развертывание NSX
Следующий этап — интеграция сетевой платформы NSX.
Если NSX ранее не использовался, VMware Cloud Foundation может автоматически
развернуть NSX Manager cluster и подготовить хосты ESX.
Если NSX уже установлен в инфраструктуре,
он может быть импортирован вместе с workload domain.
Пост-апгрейд проверки
После завершения интеграции необходимо провести проверку состояния среды.
Стоит убедиться, что workload domain корректно отображается
в интерфейсе VCF, хосты ESX подключены,
датасторы доступны, а виртуальные машины работают без ошибок.
Дополнительно рекомендуется протестировать ключевые операции виртуализации:
vMotion, создание снапшота и сетевую связность между виртуальными машинами.
Итог
Brownfield-апгрейд позволяет перевести существующую инфраструктуру
vSphere 8 в модель VMware Cloud Foundation 9 без полного
перестроения среды.
Этот подход сохраняет текущие рабочие нагрузки,
централизует управление инфраструктурой
и позволяет постепенно перейти к архитектуре частного облака.
Компания VMware выпустила новый документ "VMware vSAN Frequently Asked Questions", представляющий собой подробное руководство с ответами на наиболее распространённые вопросы о технологии VMware vSAN — программно-определяемой системе хранения (Software-Defined Storage), встроенной в гипервизор VMware ESX и используемой в средах VMware vSphere.
vSAN объединяет локальные диски серверов в общий распределённый датастор, который используется виртуальными машинами и управляется через интерфейс vSphere. Такой подход позволяет создавать гиперконвергированную инфраструктуру (HCI), где вычисления и хранение данных объединены в одном кластере серверов.
FAQ-документ охватывает широкий спектр тем:
Архитектуру vSAN (Original Storage Architecture и Express Storage Architecture)
Требования к оборудованию и сети
Варианты развертывания кластеров
Масштабирование и отказоустойчивость
Интеграцию с другими функциями VMware
Основные разделы FAQ
Вопросы распределены по большим тематическим блокам:
General Information — общая информация о vSAN
Express Storage Architecture (ESA)
Availability — отказоустойчивость
Cloud-Native Storage
vSAN File Services
vSAN Storage Clusters (disaggregated storage)
Stretched clusters и 2-node clusters
Networking
Capacity и Space Efficiency
Operations
Performance
Security
vSAN Data Protection
Каждый из этих разделов содержит от нескольких до нескольких десятков вопросов (всего более 180 вопросов и ответов), поэтому документ на 56 страниц фактически представляет собой большой справочник по эксплуатации и архитектуре vSAN. Это один из самых подробных FAQ-документов VMware по продукту vSAN, он помогает понять архитектуру решения, требования к оборудованию и лучшие практики внедрения vSAN в корпоративных средах.

 RSS
RSS